
The Trouble with “Legitimate Interest”
GDPR has a rule almost exactly like the one in Bill C-36.

GDPR has a rule almost exactly like the one in Bill C-36.

Based on the first-reading texts of Bill C-34 (June 10, 2026) and

What the Protecting Privacy and Consumer Data Act means for your business

Date: June 15, 2026 Prepared for: Newport Thomson clients with Canadian customers,

The headline On April 2, 2026, the federal government launched a formal

Let’s start with something most people in a boardroom won’t say out

For: Newport Thomson client engagements assessing Law 25 cookie compliance on Quebec-facing
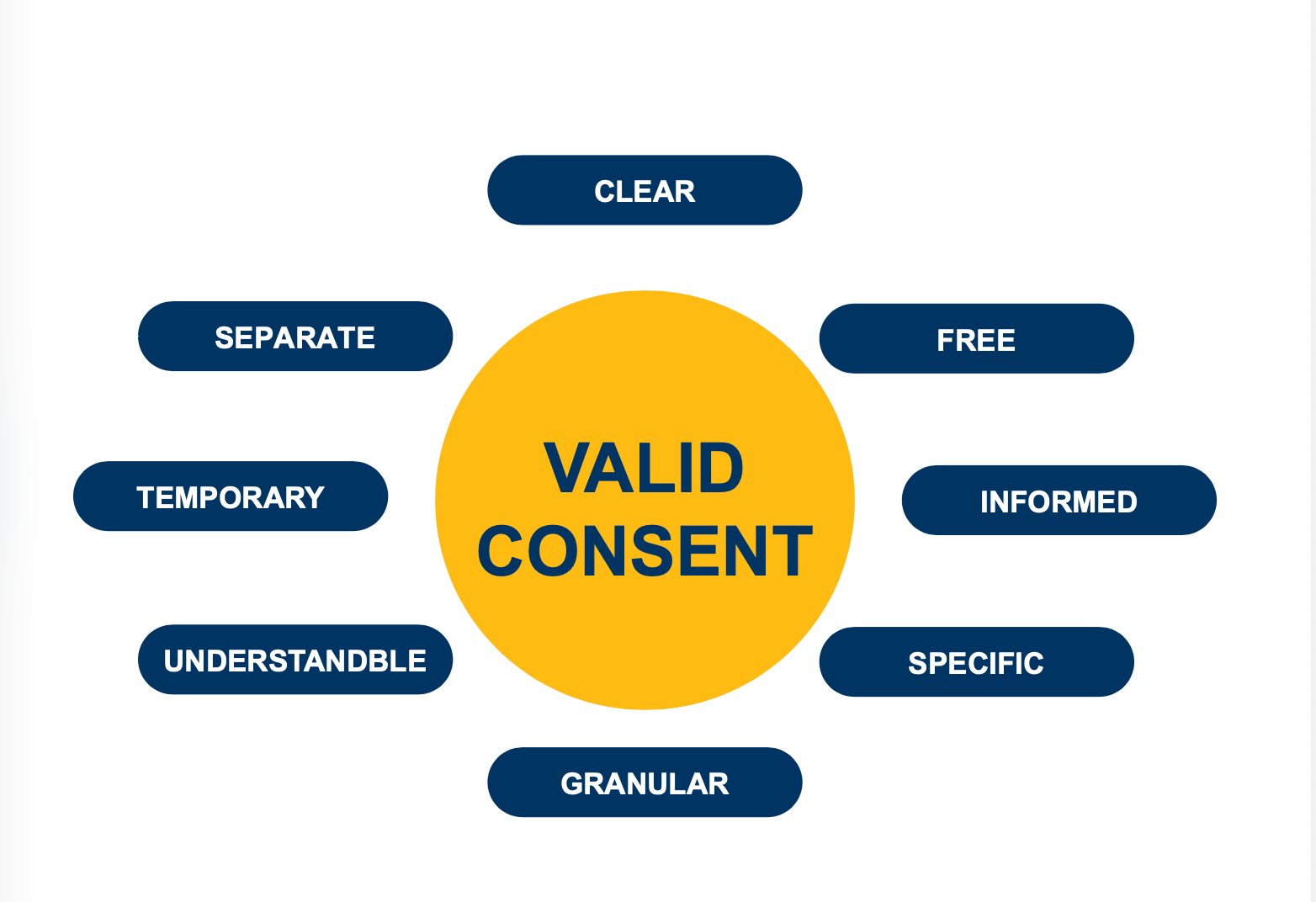
The Office of the Privacy Commissioner recently published guidance on Obtaining Meaningful

In the world of data governance, we often talk about transparency and

The recent Policy Options article, “Canada’s health data is flowing abroad while

The recent insights from MLT Aikins regarding the integration of Artificial Intelligence

Today, the Competition Bureau of Canada released a landmark report, “Your Data,
